Leetcode - K-inverse pairs array
개요
0 보다 큰 정수 n 및 k가 있다. n은 1 부터 n 까지 정수를 갖고있는 배열의 조합을 말하고 k는 inverse-pair의 개수를 뜻한다.
inverse-pair란 array의 인덱스인 i,j가 주어졌을 때, arr[i] > arr[j] 이면서 i < j를 만족하는 두 정수를 뜻한다.
예를 들어, 배열 array 가 [3,1,2] 로 주어졌을 때, inverse-pair는 [3,1], [3,2]로 만들 수 있다.
3, 1, 2 의 각 index는 0, 1, 2 이고 arr[i] > arr[j] 이면서 i < j 를 만족하는 i,j이기 때문이다.
이 때 inverse-pair가 k개수를 만족하는 array 조합의 개수를 구해야 한다.
문제 분석
base-case 분석
우선 base-case를 구해보자. k = 0이고, n = 3 일 경우 정답은 0이 나오게 된다. 왜냐하면 inverse-pair가 나오지 않는 array조합은 오름차순으로 정렬 된 [1, 2, 3] 만이 조건을 만족하기 때문이다.
작은 문제로 나눌 수 있는지 확인
n 이 3 이하의 정수이고 k가 2이하의 정수라고 가정했다. 이를 만족하는 array는 아래와 같이 나뉘어 질 수 있다.
첫 번째로 선택한 숫자에 따라 3가지 경우의 수로 나뉘어 지게 된다. 즉 n = 3 이므로 index가 0에 들어갈 숫자는 1,2 그리고 3이며 다음 index에서 남는 숫자를 다시 선택해야 한다.
그렇다면, 남는 숫자를 이용해 어떻게 문제를 나눌 수 있을까? n=3 에서 선택된 숫자를 제외한 나머지 숫자의 개수는 2개이며 각 선택된 숫자에 따라 k의 값이 달라진다. 각 숫자를 선택했을 때, 나머지 숫자들이 선택된 숫자보다 크거나 또는, 작은 경우의 수가 [그림 2]처럼 존재하게 된다.
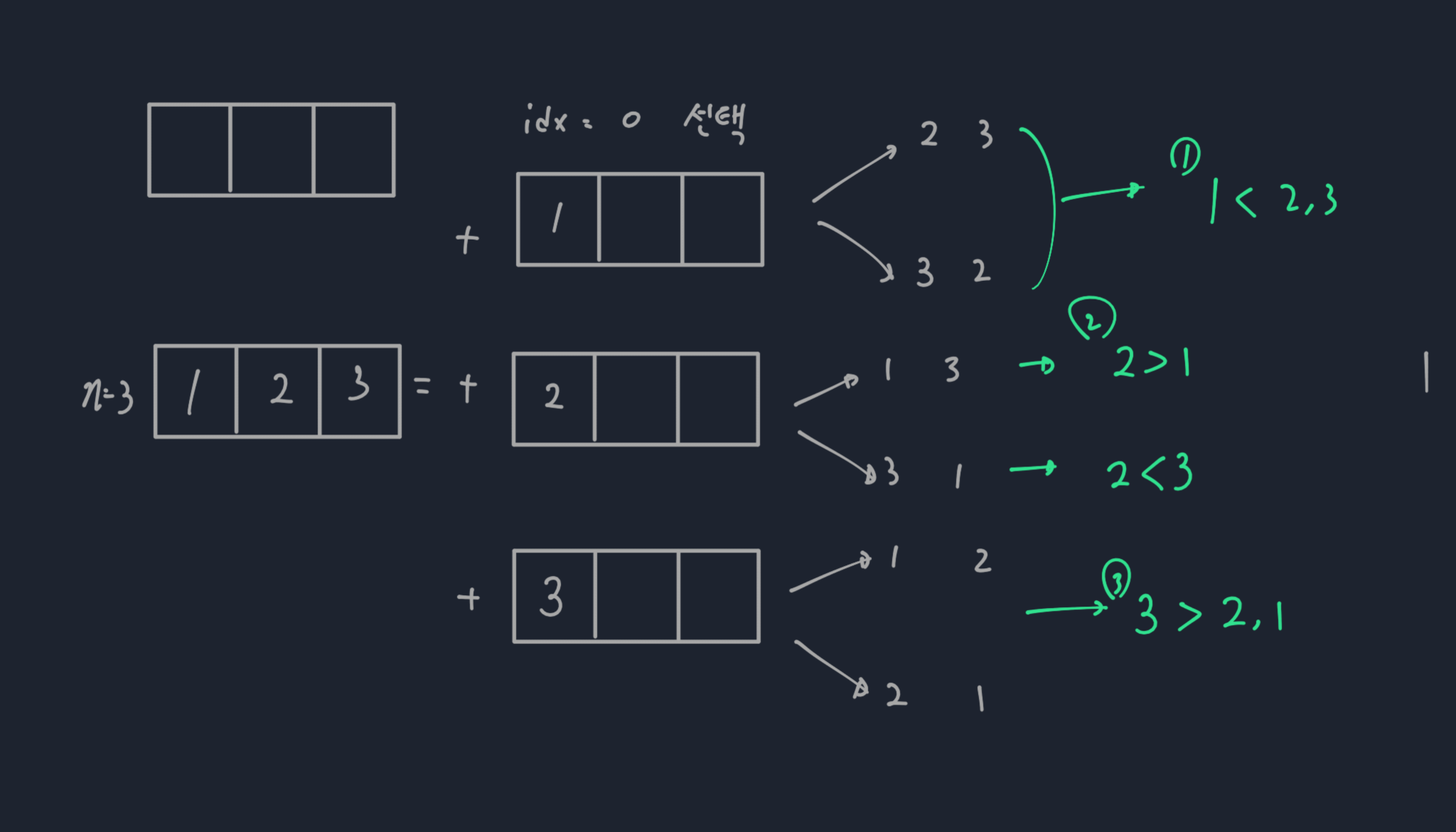
[그림 2]의 예를 들어 1을 선택하였을 때, 나머지 숫자가 2,3이며 두 숫자는 1보다 크므로 inverse-pair를 만족할 수 없다. 따라서 k의 값을 구하기 위해선 array가 [2,3]이고, k를 만족하는 수를 구해야 한다.
2를 선택했을 땐 나머지 숫자가 1,3이고 inverse-pair의 개수는 [2,1] 즉 1개이다. 따라서 따라서 구해야 할 inverse-pair는 array가 [1,3]이고 k - 1을 만족하는 수를 구해야 한다.
마지막을 3을 선택했을 땐, 나머지 숫자가 1,2이다. inverse-pair의 개수는 [3,1], [3,2] 즉 2개이다. 따라서 구해야 할 inverse-pair는 k - 2이다.
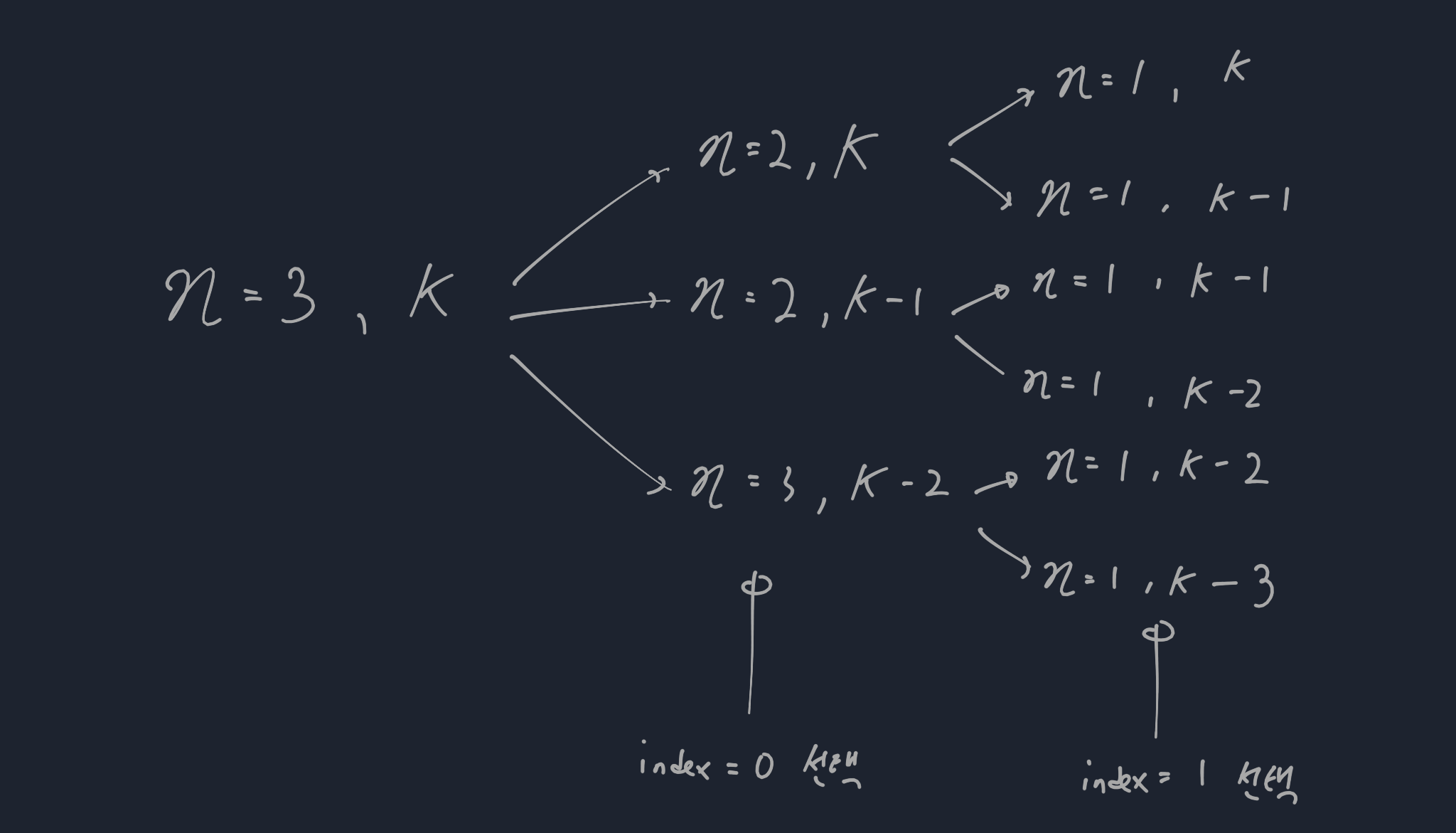
다음 의문점은 각 경우의 수들의 나머지 array들과 n = 2 인 상황과 동일한 상황일까? 즉 n = 2이면 array가 [1,2], [2,1] 인데, [그림 2]에서 나머지 array를 가지고([1,3],[2,3] 등) 동일한 결과를 만들 수 있을까? 결론부터 설명하자면 만들 수 있다. 각 array의 값들은 서로 중복이 없기 때문이다.
따라서 [그림 3]처럼 n = 3인 array는 아래와 같이 작은 문제로 쪼갤 수 있게 된다.
dynamic-programming cache 메모리 디자인
위의 문제가 작은 문제로 나뉘어 질 수 있음을 알게 되었다. 다음 과정은 미리 계산된 작은 문제들을 이용하여 큰 문제를 바로 해결할 수 있도록 작은 답들을 저장하는 cache 메모리를 디자인 해야 한다.
[그림 3]처럼 큰 문제가 여러개의 작은 문제로 나뉘어 졌음을 알았고 문제에 정답은 n 값과 k값에 의존적이기 때문에 [그림 4]처럼 2차원 배열로 표현될 수 있다. 각 n과 k의 인덱스를 n_idx, k_idx로 나타날 때, array[n_idx][k_idx]는 n = n_idx 이고, k = k_idx인 결과 값을 저장한 것이다.
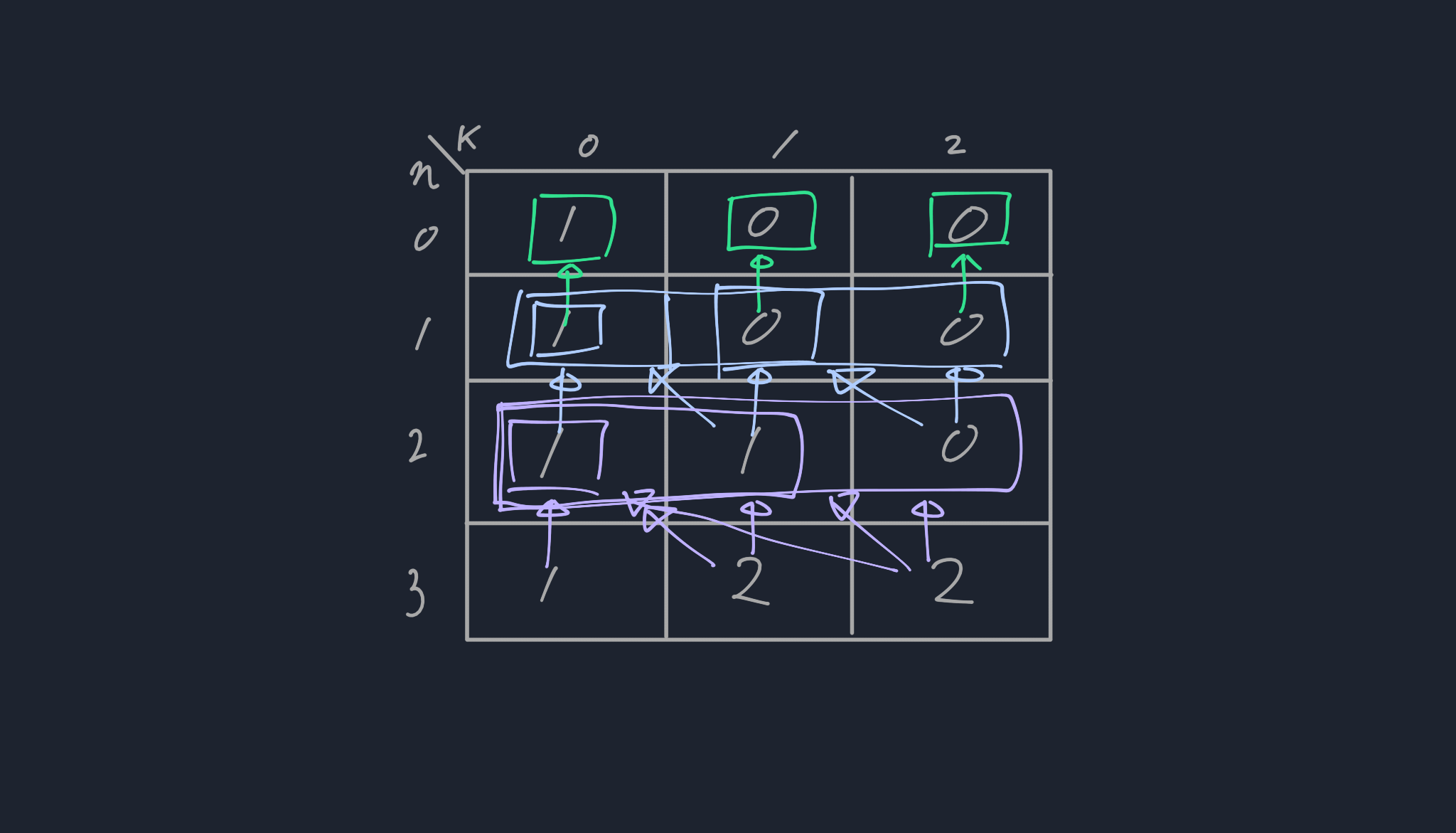
[그림 4]를 보면 규칙이 있음을 알 수 있는데, [n_idx][k_idx] 는 이전 n_idx의 길이(k_idx - n_idx - 1 부터 k_idx - 0)만큼 더하기 때문에 아래와 같이 파이썬 코드를 짤 수 있게 된다.
def kinversepair(n: int, k: int) -> int:
MOD = 10 ** 9 + 7
cache = [[0] * (k + 1) for _ in range(n + 1)]
cache[0][0] = 1
for n_idx in range(1, n + 1):
for k_idx in range(k + 1):
# k_idx - (n_idx - 1)부터 k_idx - 0까지 더함 즉 0 ~ n_idx - 1까지 iterate함
for pair in range(n_idx):
if k_idx - pair >= 0:
cache[n_idx][k_idx] += cache[n_idx - 1][k_idx - pair] % MOD
return cache[n][k]
하지만 위의 시나리오는 시간 초과가 나타나므로 조금 더 최적화 할 필요가 있다.
해결 전략
dynamic-programming cache 메모리 최적화
구하고자 하는 cache[n][k]는 n-1의 결과를 가지고, 생성되기 때문에 이전 결과 값을 덮어 쓰는 방식으로 메모리를 최적화 할 수 있다.
def kinversepair(n: int, k: int) -> int:
MOD = 10 ** 9 + 7
previous_cache = [0] * (k + 1)
previous_cache[0] = 1
for n_idx in range(1, n + 1):
current_cache = [0] * (k + 1)
for k_idx in range(k + 1):
for pair in range(n_idx):
if k_idx - pair >= 0:
current_cache[k_idx] += previous_cache[k_idx - pair] % MOD
# current_cache를 이전 결과에 덮어쓴다.
previous_cache = current_cache
return previous_cache[k]
하지만, 이 방식도 마찬가지로 시간 초과로 풀 수 없게 된다. 아무래도 Big-O가 O(n * k * n)이기 때문에 이를 깨지 않으면 시간 초과가 계속 날 것이다.
sliding-window 아이디어
여기서 등장하는 것이 sliding-window 아이디어다. sliding-window는 일정한 길이의 데이터를 처리하는 방법을 말한다. 지금과 같은 상황에서는 [그림 5]와 같이 n_idx에 따라 일정한 길이의 데이터를 표현할 수 있다.
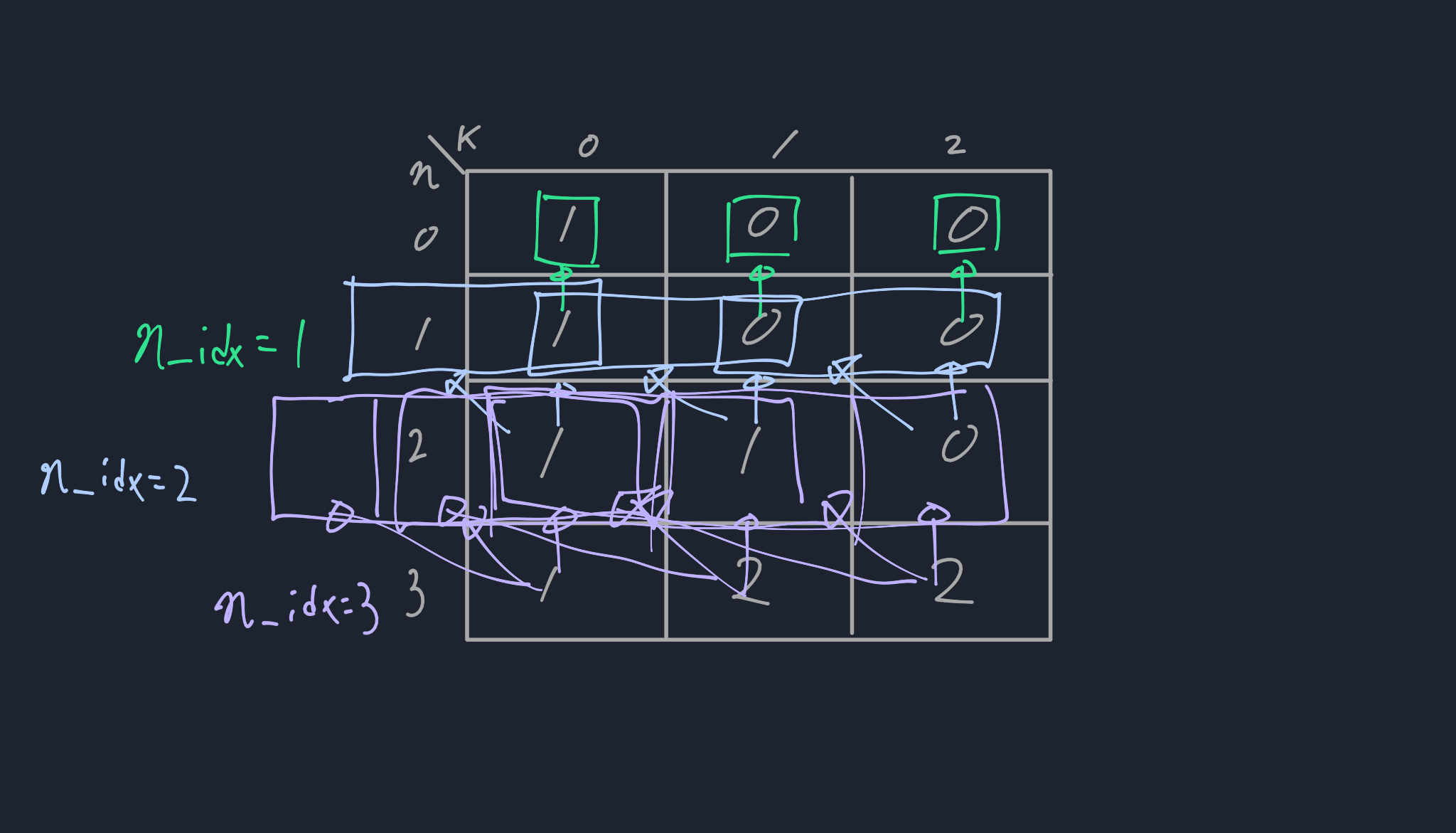
[그림 5]의 화살표 개수만큼 처리한다면, 지금까지 나왔던 소스코드의 시간 복잡도와 별 차이가 없을 것이다.
이를 최적화 하기 위해 [그림 6] 처럼 예를 들어 n_idx = 2, k_idx = 2일 때 sliding-window의 크기를 벗어난 index(k_idx - n_idx)를 누적 합에서 제거하고, 새로운 idx의 값을 추가하는 방식으로 미리 계산할 수 있다. 즉 windows_size를 유지하면서 누적으로 더할 수 있다.
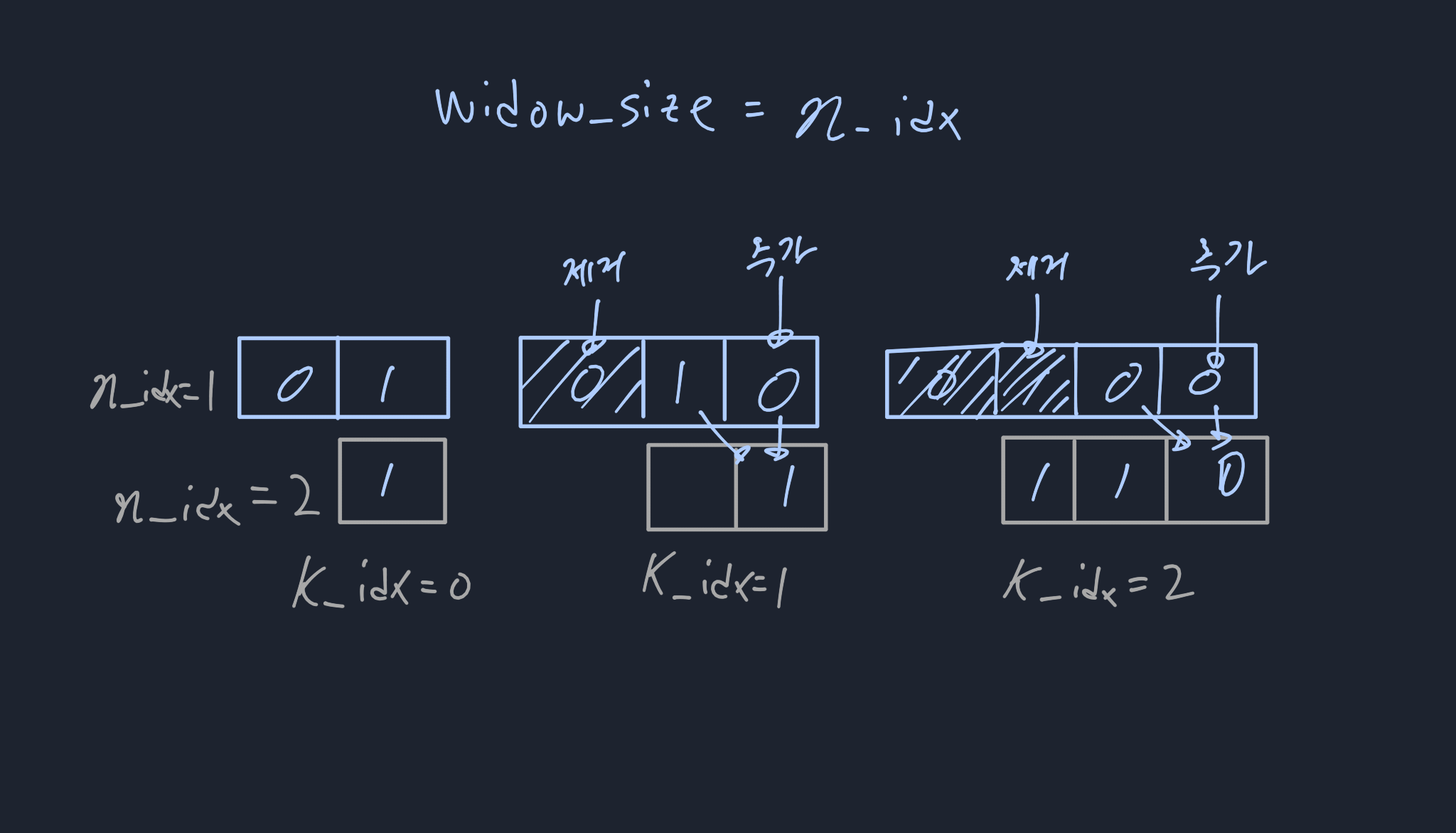
이를 반영한 코드는 아래와 같이 작성될 수 있다. 따라서, 새로운 알고리즘의 시간 복잡도를 O(n * k)로 단축시킬 수 있었다.
class Solution:
def kInversePairs(self, n: int, k: int) -> int:
MOD = 10 ** 9 + 7
previous_cache = [0] * (k + 1)
previous_cache[0] = 1
for n_idx in range(1, n + 1):
current_cache = [0] * (k + 1)
total = 0
# sliding-window 전략을 사용한다. 각 n_idx내의 window 크기는 n_idx 이다
window_size = n_idx
for k_idx in range(k + 1):
# 이전 값이 window 범위 밖에 넘어가면 총 합계에서 제거한다.
if k_idx - window_size >= 0:
total -= previous_cache[k_idx - window_size]
# 이전 총합에서 previous_cache[k_idx] 값을 새로 추가한다.
total += previous_cache[k_idx] % MOD
current_cache[k_idx] = total % MOD
previous_cache = current_cache
return previous_cache[k]