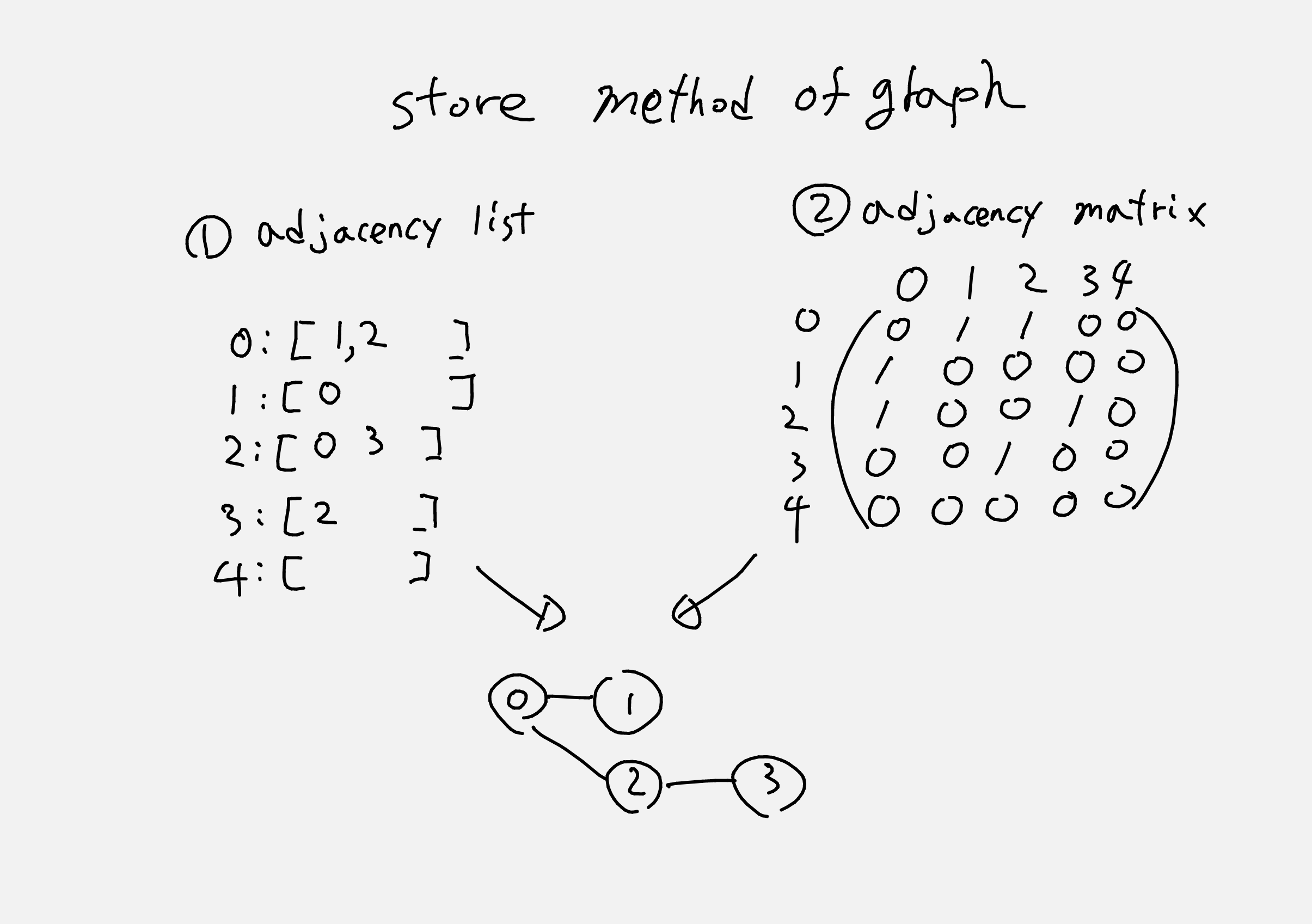
fromtypingimportListclassGraph:def__init__(self,numberofNode):self.graph={i:[]foriinrange(1,numberofNode+1)}self.numberofNode=numberofNodedefadd_edge(self,edge_info:List[int])->None:# edge_info 가 [Node1 Node2]로 되어있다고 가정Node1,Node2=edge_info# Node 연결 방법 - adjacency listself.graph[Node1].append(Node2)self.graph[Node2].append(Node1)
fromtypingimportListclassGraph:def__init__(self,numberofNode):self.graph=[[0forindexinrange(numberofNode+1)]forindexinrange(numberofNode+1)]self.numberofNode=numberofNodedefadd_edge(self,edge_info:List[int])->None:# edge_info 가 [Node1 Node2]로 되어있다고 가정Node1,Node2=edge_info# Node 연결 방법 - adjacency matrixself.graph[Node1][Node2]=1self.graph[Node2][Node1]=1
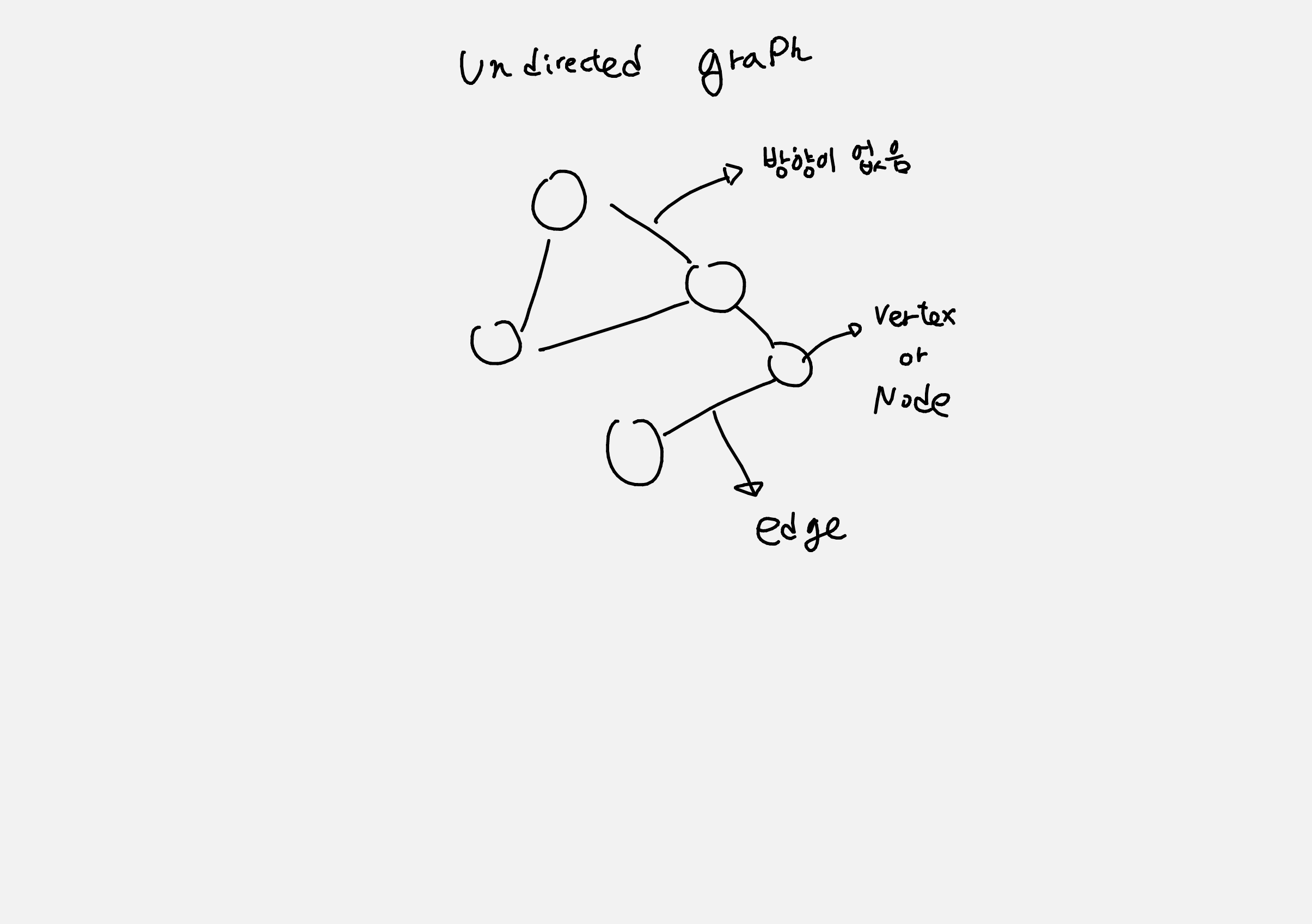
연결되어있는 Node 탐색 방법
Node 탐색방법에는 BFS, DFS가 있지만 BFS는 아직 안다루고 DFS 먼저 다룰 예정이다.
DFS는 연결된 연결된 Node의 연결된 Node의 연결된 Node의 ... 이런식으로 깊이를 우선적으로 고려하여 탐색한다.
BFS는 짧게 설명하자면 하나의 Node에서 연결된 Node 정보들 전부를 우선적으로 탐색하는 것이라고 생각하면 된다.
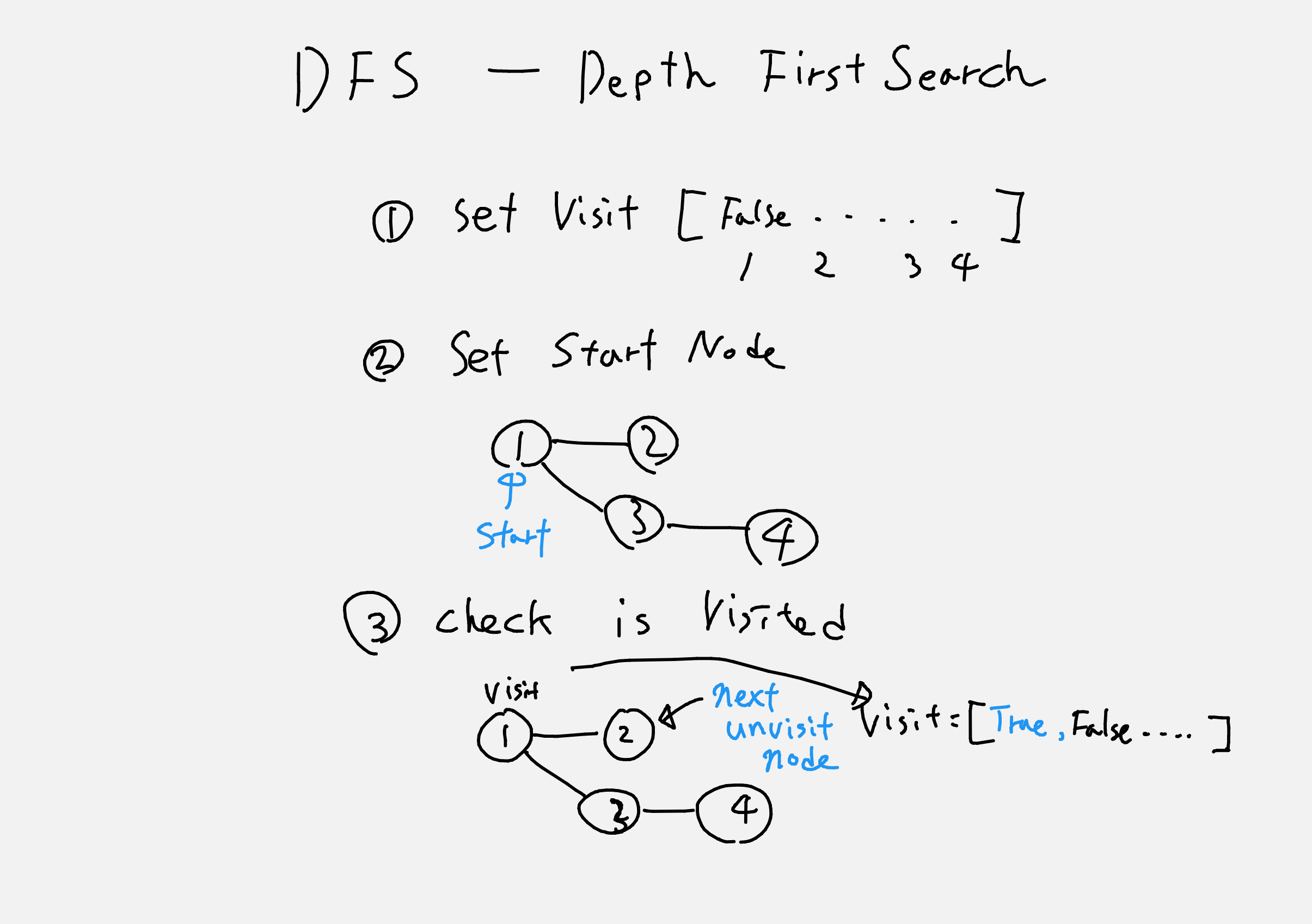
그림 3 - DFS 탐색 방법
Graph를 탐색할때는 비선형구조이기 때문에 탐색하려는 시작 Node를 우선적으로 설정해줘야 한다.
그리고 탐색 시 연결된 Node가 이미 탐색한 Node인지 아닌지 확인하기 위해 추가 정보도 필요하다.
이 추가 정보를 저장하기 위한 List형 자료형을 visit_list 라고 표현하자.
visit_list의 크기는 Node의 자료 크기 길이 즉, Node가 1번부터 10번까지 있으면, visit_list는 11(0 제외)이고 값이 전부 false인 Array이다1.
아래의 그림과 같이 탐색할 1번 Node를 선택하였다면, visit_list[1]에 True값으로 변경하고, 아직 방문하지 않은 Node가 있을경우 순차적으로 그 Node를 방문하면 된다.
방문하는 방식은 크게 2가지가 있으며 첫번 째 방법인 재귀함수를 이용한 방법 먼저 살펴보자.
DFS(Depth-First-Search) 방법 1 : visit list와 재귀함수 이용
재귀함수란, 함수의 정의에 해당 함수를 호출하는 방식으로 이루어진 함수이다.
DFS과정은 Node를 재귀적으로 탐색하는 걸 구현하는데 특화되어 있어서, 코드가 간결해진다.
classGraph:# (중략)defsearch_using_DFS2(self,start):stack=[]visit_list=[Falseforiinrange(self.numberofNode+1)]stack.append(start)whilestack:node=stack.pop()ifnotvisit_list[node]:print(node)visit_list[node]=Truestack.extend(self.get_connected_node(node))# add to visit list
문제 분석
Edge의 최대 최소를 구하기 위해서, DFS를 한개의 Node만 하는게 아니라, 저장하고 있는 Node를 전부 탐색해야 원하는 결과가 나올 것으로 예상된다.
defcomponentsInGraph(gb):# build graphgraph={i:[]foriinrange(1,len(gb)*2+1)}# set 1 to 2N graph# add edgeforn,vingb:graph[n].append(v)graph[v].append(n)# dfs searchcluster_count_list=[]visited=[False]*((len(gb)*2)+1)# set visited listforstart_pointingraph:ifnotvisited[start_point]:cluster_count_list.append(0)stack=[start_point]whilestack:node=stack.pop()ifnotvisited[node]:visited[node]=Truecluster_count_list[-1]+=1forvertexingraph[node]:ifnotvisited[vertex]:stack.append(vertex)ifcluster_count_list[-1]==1:cluster_count_list.pop()return[min(cluster_count_list),max(cluster_count_list)]
3줄과 11줄에서 문제의 조건에 따라 최대 Node 데이터의 범위대로 공간을 할당하고,
12줄에서 graph 내에 있는 Node들의 Edge를 전부 탐색하여 최대 최소를 구하기 위해 cluster_count_list 자료형에 연결된 Edge개수를 저장하고 있다.